How to calculate a Pokemons 'power level' using kmeans
Table of Contents
knitr::opts_chunk$
The Heros Journey
Pokemon games have a very familiar cycle. You start with one of 3 Pokemon. You adventure out with your new buddy, facing tougher and tougher Pokemon, in greater variety. Many of your Pokemon evolve over time, and eventually you find the end-game legendaries in a climactic battle of titans!
You can even see this story in the data. Here is the base_experience of all the Pokemon, identified by game generation. The base_experience is the basic amount of experience that is gained by the winner of a battle from a specific species. e.g. If you beat a Bulbasaur, your Pokemon gains experience based on a formula which uses Bulbasaurs base_experience. Because of that we can see it as a proxy value for how powerful a Pokemon is. If it’s more powerful, it will be harder to beat, and so reward you with more experience when you win.
pokemon %>%
+
+
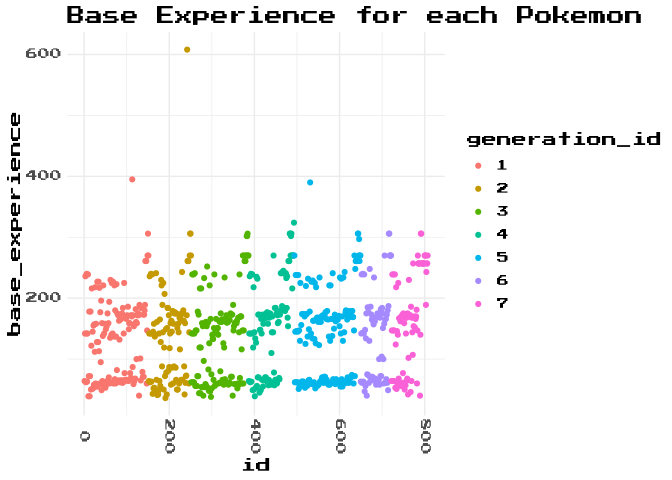
In each generation you can see a few attributes:
- power level - 3(ish) tiers, grouped in different vertical lanes
- progression - a (generally) increasing trend in the base power value
- the up-ticks at the start and the end of each gen are the starters top-tier evolution (Woo Blastoise!) and the Legendaries at the end-game
Lets see if we can group each Pokemon into a power_level. A categorical grouping which relates it to other Pokemon with similar base_experience
Grouping and counting
Maybe we can explicitly describe the power levels of each tier of Pokemon with a simple process? Can we group each Pokemon by evolutionary chain, and then count each Pokemons order within the group?
pokemon %>%
%>%
-> pokemon_group_count
+
+
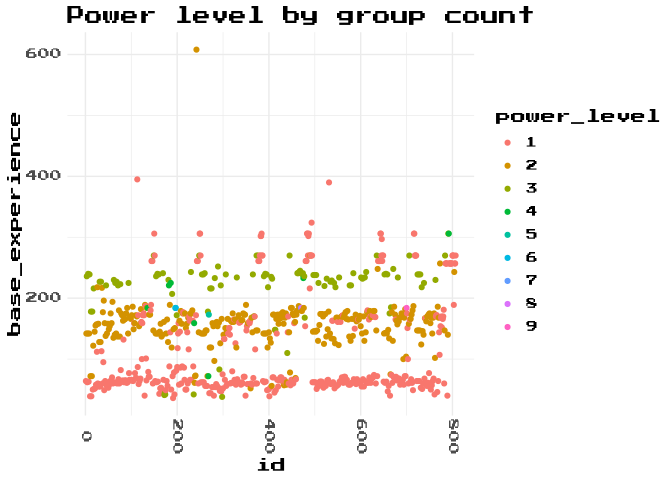
Sort of? Generally we capture the pattern, but we don’t actually get it very right. First off, there are more than 3 evolutionary tiers in our engineered feature. We can also see there are some Pokemon are classified as a power_level higher than 1, but still in the lowest group on this list. Why might have caused this?
pokemon_group_count %>%
%>%
-> pokemon_group_count_mistakes
pokemon_group_count %>%
%>%
%>%
%>%
%>%
knitr::
| id | name | base_experience | evolution_chain_id | power_level |
|---|---|---|---|---|
| 43 | Oddish | 64 | 18 | 1 |
| 44 | Gloom | 138 | 18 | 2 |
| 45 | Vileplume | 221 | 18 | 3 |
| 182 | Bellossom | 221 | 18 | 4 |
| 60 | Poliwag | 60 | 26 | 1 |
| 61 | Poliwhirl | 135 | 26 | 2 |
| 62 | Poliwrath | 230 | 26 | 3 |
| 186 | Politoed | 225 | 26 | 4 |
| 106 | Hitmonlee | 159 | 47 | 1 |
| 107 | Hitmonchan | 159 | 47 | 2 |
| 236 | Tyrogue | 42 | 47 | 3 |
| 237 | Hitmontop | 159 | 47 | 4 |
| 133 | Eevee | 65 | 67 | 1 |
| 134 | Vaporeon | 184 | 67 | 2 |
| 135 | Jolteon | 184 | 67 | 3 |
| 136 | Flareon | 184 | 67 | 4 |
| 196 | Espeon | 184 | 67 | 5 |
| 197 | Umbreon | 184 | 67 | 6 |
| 470 | Leafeon | 184 | 67 | 7 |
| 471 | Glaceon | 184 | 67 | 8 |
| 700 | Sylveon | 184 | 67 | 9 |
| 265 | Wurmple | 56 | 135 | 1 |
| 266 | Silcoon | 72 | 135 | 2 |
| 267 | Beautifly | 178 | 135 | 3 |
| 268 | Cascoon | 72 | 135 | 4 |
| 269 | Dustox | 173 | 135 | 5 |
| 280 | Ralts | 40 | 140 | 1 |
| 281 | Kirlia | 97 | 140 | 2 |
| 282 | Gardevoir | 233 | 140 | 3 |
| 475 | Gallade | 233 | 140 | 4 |
| 789 | Cosmog | 40 | 413 | 1 |
| 790 | Cosmoem | 140 | 413 | 2 |
| 791 | Solgaleo | 306 | 413 | 3 |
| 792 | Lunala | 306 | 413 | 4 |
So there are some clear problems with this approach. In Gen 1 we had some branching evolution with the Eevee family. Not only was this family expanded in multiple generations to eventually 8 variations, but we also saw more branching evolution trees as well. We also got ‘baby’ Pokemon. Pokemon that are actually pre-cursors to other Pokemon, but are listed later in the Pokedex.
Luckily there is another variable we can use, that should be a whole lot better.
evolves_from_species
Each Pokemon that evolves from another Pokemon has the Pokemon they evolve froms id as the value in the evolves_from_species_id variable. Maybe we can use that to break up the Pokemon into their ‘power levels’.
The following code is not my best work, however I spent some time on a more recursive strategy, but it was honestly miles more confusing. For the purposes of a silly example for a blog, I think this is prefferable.
pokemon %>%
%>%
-> pokemon_1
pokemon %>%
%>%
-> pokemon_2
pokemon %>%
%>%
-> pokemon_3
%>%
%>%
-> pokemon_evolves_from
pokemon_evolves_from %>%
+
+
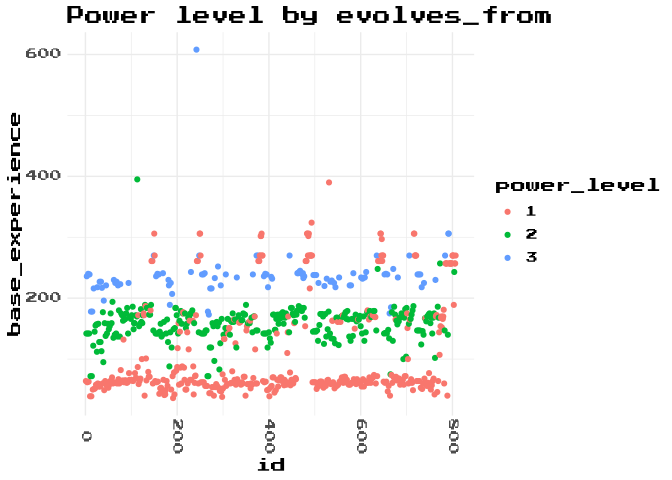
Hmm, that’s actually worse? Lets focus on the Pokemon labelled power_level 1, but are up where we would expect level 3 Pokemon to be.
pokemon_evolves_from %>%
%>%
%>%
knitr::
| id | name | base_experience |
|---|---|---|
| 144 | Articuno | 261 |
| 145 | Zapdos | 261 |
| 146 | Moltres | 261 |
| 150 | Mewtwo | 306 |
| 151 | Mew | 270 |
| 243 | Raikou | 261 |
| 244 | Entei | 261 |
| 245 | Suicune | 261 |
| 249 | Lugia | 306 |
| 250 | Ho-Oh | 306 |
| 251 | Celebi | 270 |
| 377 | Regirock | 261 |
| 378 | Regice | 261 |
| 379 | Registeel | 261 |
| 380 | Latias | 270 |
| 381 | Latios | 270 |
| 382 | Kyogre | 302 |
| 383 | Groudon | 302 |
| 384 | Rayquaza | 306 |
| 385 | Jirachi | 270 |
| 386 | Deoxys | 270 |
| 480 | Uxie | 261 |
| 481 | Mesprit | 261 |
| 482 | Azelf | 261 |
| 483 | Dialga | 306 |
| 484 | Palkia | 306 |
| 485 | Heatran | 270 |
| 486 | Regigigas | 302 |
| 487 | Giratina | 306 |
| 488 | Cresselia | 270 |
| 489 | Phione | 216 |
| 490 | Manaphy | 270 |
| 491 | Darkrai | 270 |
| 492 | Shaymin | 270 |
| 493 | Arceus | 324 |
| 494 | Victini | 270 |
| 531 | Audino | 390 |
| 638 | Cobalion | 261 |
| 639 | Terrakion | 261 |
| 640 | Virizion | 261 |
| 641 | Tornadus | 261 |
| 642 | Thundurus | 261 |
| 643 | Reshiram | 306 |
| 644 | Zekrom | 306 |
| 645 | Landorus | 270 |
| 646 | Kyurem | 297 |
| 647 | Keldeo | 261 |
| 648 | Meloetta | 270 |
| 649 | Genesect | 270 |
| 716 | Xerneas | 306 |
| 717 | Yveltal | 306 |
| 718 | Zygarde | 270 |
| 719 | Diancie | 270 |
| 720 | Hoopa | 270 |
| 721 | Volcanion | 270 |
| 785 | Tapu Koko | 257 |
| 786 | Tapu Lele | 257 |
| 787 | Tapu Bulu | 257 |
| 788 | Tapu Fini | 257 |
| 793 | Nihilego | 257 |
| 794 | Buzzwole | 257 |
| 795 | Pheromosa | 257 |
| 796 | Xurkitree | 257 |
| 797 | Celesteela | 257 |
| 798 | Kartana | 257 |
| 799 | Guzzlord | 257 |
| 800 | Necrozma | 270 |
| 801 | Magearna | 270 |
| 802 | Marshadow | 270 |
| 805 | Stakataka | 257 |
| 806 | Blacephalon | 257 |
| 807 | Zeraora | 270 |
So these Pokemon are nearly all ‘Legendary’. They are big end-game Pokemon, with real rarity in game. They also don’t evolve from, or to, anything, so our rule doesn’t classify them effectively.
pokemon_evolves_from %>%
%>%
%>%
knitr::
| id | name | base_experience |
|---|---|---|
| 83 | Farfetch’d | 132 |
| 115 | Kangaskhan | 172 |
| 127 | Pinsir | 175 |
| 128 | Tauros | 172 |
| 131 | Lapras | 187 |
| 132 | Ditto | 101 |
| 142 | Aerodactyl | 180 |
| 201 | Unown | 118 |
| 203 | Girafarig | 159 |
| 206 | Dunsparce | 145 |
| 213 | Shuckle | 177 |
| 214 | Heracross | 175 |
| 222 | Corsola | 144 |
| 225 | Delibird | 116 |
| 227 | Skarmory | 163 |
| 234 | Stantler | 163 |
| 241 | Miltank | 172 |
| 302 | Sableye | 133 |
| 303 | Mawile | 133 |
| 311 | Plusle | 142 |
| 312 | Minun | 142 |
| 313 | Volbeat | 151 |
| 314 | Illumise | 151 |
| 324 | Torkoal | 165 |
| 327 | Spinda | 126 |
| 335 | Zangoose | 160 |
| 336 | Seviper | 160 |
| 337 | Lunatone | 161 |
| 338 | Solrock | 161 |
| 351 | Castform | 147 |
| 352 | Kecleon | 154 |
| 357 | Tropius | 161 |
| 359 | Absol | 163 |
| 369 | Relicanth | 170 |
| 370 | Luvdisc | 116 |
| 417 | Pachirisu | 142 |
| 440 | Happiny | 110 |
| 441 | Chatot | 144 |
| 442 | Spiritomb | 170 |
| 455 | Carnivine | 159 |
| 479 | Rotom | 154 |
| 538 | Throh | 163 |
| 539 | Sawk | 163 |
| 550 | Basculin | 161 |
| 556 | Maractus | 161 |
| 561 | Sigilyph | 172 |
| 587 | Emolga | 150 |
| 594 | Alomomola | 165 |
| 615 | Cryogonal | 180 |
| 618 | Stunfisk | 165 |
| 621 | Druddigon | 170 |
| 626 | Bouffalant | 172 |
| 631 | Heatmor | 169 |
| 632 | Durant | 169 |
| 676 | Furfrou | 165 |
| 701 | Hawlucha | 175 |
| 702 | Dedenne | 151 |
| 707 | Klefki | 165 |
| 741 | Oricorio | 167 |
| 764 | Comfey | 170 |
| 765 | Oranguru | 172 |
| 766 | Passimian | 172 |
| 771 | Pyukumuku | 144 |
| 772 | Type: Null | 107 |
| 774 | Minior | 154 |
| 775 | Komala | 168 |
| 776 | Turtonator | 170 |
| 777 | Togedemaru | 152 |
| 778 | Mimikyu | 167 |
| 779 | Bruxish | 166 |
| 780 | Drampa | 170 |
| 781 | Dhelmise | 181 |
| 803 | Poipole | 189 |
These Pokemon are not end game, but they either have very short evolution trees (2 Pokemon long), or no evolution tree at all.
So our ‘group count’ process doesn’t work well, and neither does our ‘evolves_from_species’ process. We’re going to have to to learn some new moves.
TM01 (e.g. Tidy Models 01)
Clustering is the process of using machine learning to derive a categorical variable from data. The simplest form of clustering that seems relevant to our problem is k-means. Seeing as we have a pretty good intuition that 3 groups implicitly exist in this data, and a clear visualisation supporting us, lets cut straight to asking R for 3 groups. k-means clustering aims to divide the data into a known number of groups which is set in the centers argument, and doesn’t require any data to be fed to it as examples of what makes up a ‘group’. That sentence might be a little confusing, as we do obviously give it some data. What we don’t give it is a training data set which has examples of what Pokemon are supposed to be in a given group, labelled with the group they are supposed to be in, e.g. Squirtle is in group 1, Wartortle is in group 2, Blastoise is in group 3, and then give it unlabelled data to classify, e.g. “What group is Charmeleon in?”. k-means will figure out how to split the continuous variable base_experience into 3 groups.
pokemon %>%
%>%
%>%
-> pokemon_cluster
How kmeans works
First, we set centroids to be at random positions in the data. To make sure this doesn’t effect consistency in my article I’ve used set.seed so k-means starts looking for the centres of our clusters from the same position each time. A ‘centroid’ can be seen as a ‘centre point’ for each cluster. We have the same number of centroids set as the value set in the centers argument. Each data point is then assigned to it’s closest centroid.
The Sum of Squared Errors (SSE) from the centroids is then used as an objective function towards a local minimum.
This is the core concept of how k-means calculates a solution. The Sum of Squared Errors are calculated like this:
{% katex %} \sum^n_{i-1}(x_i-\bar{x})^2 {% endkatex %}
What this means is for each group, the distance from the centroid to each observation is measured, and then squared. Then each of those squared distances, one per observation in the group, is totalled.
The centroid is then moved to the average value of it’s group. Because the centroids are now no longer in the same position as when the SSE was calculated, the SSE is now recalculated for all observations, to each of the new centroid positions. This means that some observations are now closer to a different centroid, and so get assigned to a different cluster.
Then the centroids are moved again to the new average of the new cluster. Each cluster then gets new distances calculated. This will go on until termination when, each centroid is in the average position of the cluster, and each observation in the cluster is closest to the centroid it is currently assigned to.
That’s a slightly wordy description of a complicated process. I recommend that you have a look at the k-means explanation in tidy models to really cement the concept. It also contains the most adorable animation of a statistical concept in existance.
How to use it
Here, I’ve simply selected the one column of data, base_experience, and piped it into kmeans, which is part of base R. This returns a super un-tidy list like object of class "kmeans", however, with tidymodels we can easily make it usable.
augment helps us to match the output of the kmeans function back to our data for easier processing. The output of kmeans doesn’t actually contain any of the other information about our data, it only got given one column remember? augment goes through the return of kmeans, finds the relevant bit, and matches it neatly back to our original data ready for plotting in one step!
pokemon_cluster %>%
+
+
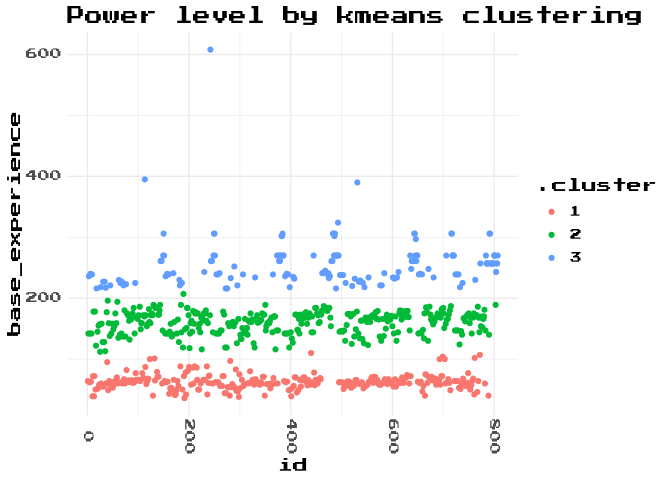
This is a lot better. It gives us really clear groups, in exactly where we expected them. It’s also tonnes simpler code!
Lets check some of our boundary positions, just to make sure it makes sense.
pokemon_cluster %>%
%>%
%>%
knitr::
| id | name | base_experience |
|---|---|---|
| 132 | Ditto | 101 |
| 440 | Happiny | 110 |
| 699 | Aurorus | 104 |
| 762 | Steenee | 102 |
| 772 | Type: Null | 107 |
pokemon_cluster %>%
%>%
%>%
knitr::
| id | name | base_experience |
|---|---|---|
| 189 | Jumpluff | 207 |
Ditto and Type: Null are just a plain weird Pokemon due to their abilities messing with their type. Happiny is a baby type, but from a family with an insane base_experience. Jumpluff is an awkward edge case. Technically the 3rd evolution, it’s still got an extremely low base_experience. Potentially this is for game balancing as they are relatively regularly encountered? Aurorus and Steenee I do not have a good hypothesis for.
Generally I think that this is a pretty good solution. There are maybe a few edge cases that are open to interpretation, but that’s just what we get sometimes with machine learning. Lacking a labelled training data set, we can’t compute a confusion matrix or ROC-curve.
Conclusion
We’ve found a situation in the ‘real’ world where we know from context there is a categorical relationship, but from the data available it’s not possible to classify that precisely. However we can create this categorisation using machine learning! Even better, we can use the tidymodels package to help us do it quickly and cleanly.